### Topic Modeling
#####appliqué aux fils twitters.
* Alexis Perrier [@alexip](https://twitter.com/alexip)
* Data & Software, Berklee College of Music, Boston [@BerkleeOnline](https://twitter.com/berkleeonline)
* Data Science contributor [@ODSC](https://twitter.com/odsc)
**Part I: Topic Modeling**
* Nature et application
* Algos et Librairies
**Part II: Projet: followers sur twitter**
* Methodes
* Problemes
* Viz
Sôrry pour les accents et anglicismes
Analyse sémantique de collections de documents

- Divers Corpus
- Littérature
- Journaux
- Documents officiels
- Contenu en ligne
- Réseaux sociaux, forums, ....
-
Couplé a des variables externes
- Evolution dans le temps
- Auteurs, locuteurs
#### Principaux Algorithmes
* Approche vectorielle
* Latent Semantic Analysis (LSA)
* Approche probabiliste, Bayésienne
* Latent Dirichlet Allocation (LDA)
* **Structural Topic Modeling (STM)**, pLSA, hLDA, ...
* Approche Neural Networks
* convnets, ...
###### Librairies
* Python libraries
* **[Gensim](https://radimrehurek.com/gensim/)** - Topic Modelling for Humans
* LDA Python library
* R packages
* a. lsa package
* b. lda package
* c. topicmodels package
* d. **[stm package](https://structuraltopicmodel.com/)**
* Java libraries: S-Space Package, MALLET
* C/C++ libraries: lda-c, hlda c, ctm-c d, hdp
#### Le Projet
3 articles
* [Topic Modeling of twitter followers](https://alexisperrier.com/nlp/2015/09/04/topic-modeling-of-twitter-followers)
* [Segmentation of Twitter Timelines via Topic Modeling](/nlp/2015/09/16/segmentation_twitter_timelines_lda_vs_lsa.html)
* [NLP Analysis of the 2015 presidential candidate debates](/nlp/2015/11/12/nlp-analysis-presidential-debates.html)
#### Etapes:
1. Construire le corpus
2. Appliquer les modeles
3. Interpreter => Perplexité!
#### Construire le corpus
1. Obtenir les timelines des 700 followers de [@alexip](https://twitter.com/alexip): [Twython](https://twython.readthedocs.org/en/latest/)
Un document correspond a une timeline
2. Vectoriser le document
* bag-of-words
* Timeline en anglais: lang = 'en' + [langid](https://github.com/saffsd/langid.py)
* [NLTK](https://www.nltk.org/): tokenize, stopwords, stemming, POS
3. TF-IDF
* Creer un dictionnaire de mots
* Vectoriser les documents TF-IDF
* Gensim, NLTK, Scikit, ....
#### 1) Appliquer LSA
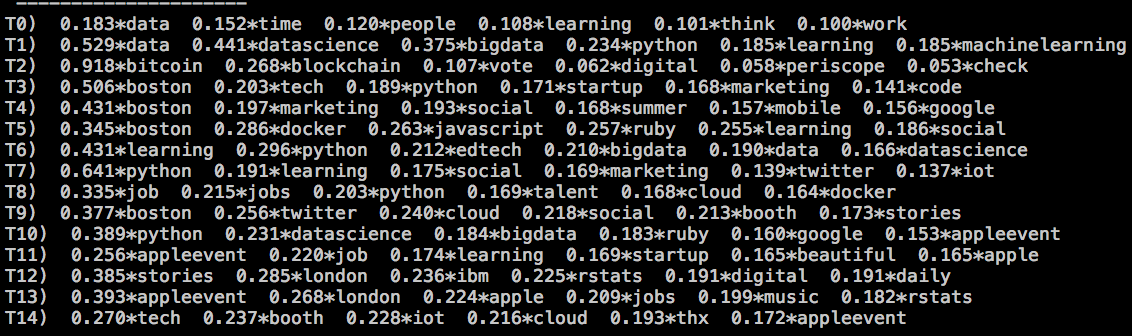
Résultats pour le moins difficiles a interpreter

#### 2) Appliquer LDA
Franchement mieux
u'0.055*app + 0.045*team + 0.043*contact + 0.043*idea + 0.029*quote + 0.022*free + 0.020*development + 0.019*looking + 0.017*startup + 0.017*build',
u'0.033*socialmedia + 0.022*python + 0.015*collaborative + 0.014*economy + 0.010*apple + 0.007*conda + 0.007*pydata + 0.007*talk + 0.007*check + 0.006*anaconda',
u'0.053*week + 0.041*followers + 0.033*community + 0.030*insight + 0.010*follow + 0.007*world + 0.007*stats + 0.007*sharing + 0.006*unfollowers + 0.006*blog',
u'0.014*thx + 0.010*event + 0.008*app + 0.007*travel + 0.006*social + 0.006*check + 0.006*marketing + 0.005*follow + 0.005*also + 0.005*time',
u'0.044*docker + 0.036*prodmgmt + 0.029*product + 0.018*productmanagement + 0.017*programming + 0.012*tipoftheday + 0.010*security + 0.009*javascript + 0.009*manager + 0.009*containers',
u'0.089*love + 0.035*john + 0.026*update + 0.022*heart + 0.015*peace + 0.014*beautiful + 0.012*beauty + 0.010*life + 0.010*shanti + 0.009*stories',
u'0.033*geek + 0.009*architecture + 0.007*code + 0.007*products + 0.007*parts + 0.007*charts + 0.007*software + 0.006*cryptrader + 0.006*moombo + 0.006*book',
u'0.049*stories + 0.046*network + 0.044*virginia + 0.044*entrepreneur + 0.039*etmchat + 0.025*etmooc + 0.021*etm + 0.015*join + 0.014*deis + 0.010*today',
u'0.056*slots + 0.053*bonus + 0.052*fsiug + 0.039*casino + 0.031*slot + 0.024*online + 0.014*free + 0.013*hootchat + 0.010*win + 0.009*bonuses',
u'0.056*video + 0.043*add + 0.042*message + 0.032*blog + 0.027*posts + 0.027*media + 0.025*training + 0.017*check + 0.013*gotta + 0.010*insider'
* Quels sont les topics?
* Combien de topics?
#### Back to the corpus
* Nettoyage des documents
* Completer la liste des stopwords a la main
* Identifier les anomalies: Robots, retweets, hastag, ...
* Ne garder que les fils qui ont twitté récemment.
245 timelines
[Visualization - LDAvis](https://nbviewer.jupyter.org/github/alexisperrier/datatalks/blob/master/twitter/LDAvis_V2.ipynb#topic=4&lambda=0.57&term=)
#### 3) Structural Topic Modeling
* NLP: Tokenization, stemming, stop-words, ...
* Nommer les topics: plusieurs groupes de mots par topic exclusivité, fréquence
* Nombre de topic optimum: grid search + scoring
* Influence des variables externes
#### STM: Presidential debates
* Primaires US
* 6 debats: 2 democrates, 4 republicains
* 1 document = un intervenant pendant un debat
[Visualization - stmBrowser](https://alexisperrier.com/stm-visualization/index.html)
Code & Data & Viz:
- https://github.com/alexisperrier/datatalks/tree/master/twitter
- https://github.com/alexisperrier/datatalks/tree/master/debates
- https://nbviewer.jupyter.org/github/alexisperrier/datatalks/blob/master/twitter/LDAvis_V2.ipynb
- https://alexisperrier.com/stm-visualization/index.html
Ref:
- topic modeling https://thesai.org/Downloads/Volume6No1/Paper_21-A_Survey_of_Topic_Modeling_in_Text_Mining.pdf
- lda: https://ai.stanford.edu/~ang/papers/nips01-lda.pdf
- pyLDAvis: https://github.com/bmabey/pyLDAvis
- stm: https://scholar.princeton.edu/files/bstewart/files/stmnips2013.pdf
- stm R: https://structuraltopicmodel.com/
- stmBrowser: https://github.com/mroberts/stmBrowser