In this post, we explore LDA an unsupervised topic modeling method in the context of twitter timelines. Given a twitter account, is it possible to find out what subjects its followers are tweeting about?
Knowing the evolution or the segmentation of an account’s followers can give actionable insights to a marketing department into near real time concerns of existing or potential customers. Carrying topic analysis of followers of politicians can produce a complementary view of opinion polls.
The goal of this post is to explore my own followers, 698 at time of writing and find out what they are tweeting about through Topic Modeling of their timelines.
We use Python 2.7 and the following packages and methods:
- Gensim, an NLP package for Topic Modeling
- Latent Dirichlet Allocation to extract topics within a set of documents
- NLTK for stop words, ponctuation, tokenization and lemmatization
And
- Twython a Python wrapper for the Twitter API to extract the twitter data
- We store the twitter data in a MongoDb collection via PyMongo.
Obtaining Twitter data is not straightforward and takes time since Twitter limits the number of requests one can make in a given amount of time. This forces us to include waiting periods when querying the API. In order to avoid having to query Twitter everytime we want to access the original data, we save all the tweets in a MongoDB database. Since the MongoDB database does not need a predefined static schema this allows us to extend the data structure on the fly if needed.
Extracting the data from Twitter
We only need OAuth2 authentication which is simpler to implement than OAuth1. Once you have obtained your OAuth2 keys and ACCESS_TOKEN, Twython makes it easy to retrieve a list of followers or tweets from a timeline. There is a one to one correspondance between the Twython method and the twitter API call. For each follower we store, the (max) 200 most recent tweets, the language of the account, the number of tweets obtained and the screenname of the account.
The python code to extract the data from twitter is available here
Aggregate tweets into documents
We create one document per follower by aggregating his / her tweets. Each follower then has a unique document which serves as the basis for our topic analysis.
Lang
Having documents in several languages will add noise to the topic extraction and we want to filter out timelines that are not 100% in English. Filtering users by the ‘lang’ parameter of their twitter account is not 100% reliable. Some users tweet in several languages although their account language is declared as ‘en’ while others have not defined the language of their account. (lang = ‘und’ for undefined).
To filter out non English timelines we first filter out accounts that have a lang attribute not set to ‘en’ or ‘und’ and then use the langid library to further refine our selection.
Other methods using NLTK stopwords (see also this post) or character trigrams could also be considered to detect the language at the tweet level. However since we have documents that are collection of tweets and have a large enough number of words, the langid method is the simplest.
And we end up with 472 documents.
In the meantime, I learned that I had followers in Japanese, French, Russian, Chzech, Spanish, Potuguese, Italian, Dutch and Greek!
Extracting the signal from the noise
We then clean up and prepare the documents for LDA
- Remove URLs
- Remove documents with less than 100 words
- Tokenize: aka breaking the documents into words. This also remove punctuation.
- Remove stop words, words that only occur once, digits and words composed of only 1 or 2 characters
Then we build a dictionary where for each document, each word has its own id. We end up with a dictionary of 24402 tokens. And finally we build the corpus i.e. vectors with the number of occurence of each word for each document.
This cleanup process was iterative. Looking at the LDA results allowed us to detect frequent words that did not add any meaning to the documents and include them in the stopword list for another cleanup run.
The python code used to process the raw documents is available here
Topic Modeling via LDA
Now we are ready to find what the followers of alexip are tweeting about.
Finding the right parameters for LDA is ‘an art’. 3 main parameters need to be optimized:
- K: the number of topics
- Alpha which dictates how many topics a document potentially has. The lower alpha, the lower the number of topics per documents
- Beta which dictates the number of word per document. Similarly to Alpha, the lower Beta is, the lower the number for words per topic.
Since we are dealing with tweets, I assumed that each follower would have a limited number of topics to tweet about and therefore set alpha to a low value 0.001. (default value is 1.0/num_topics). I left beta to its default setting.
We tried several values for K the number of topics. Too few topics result in heterogeneous set of words while too many diffuse the information with the same words shared across many topics. For the record, there are several different ways to estimate the optimum number of topic in a corpus. See also the Hierarchical Dirichlet Process (HDP) which is an extension of LDA where the number of topics is infered from the data and does not have to be specified beforehand.
The default view of the top 10 topics is not the most user-friendly one. For each topic it lists the top 10 words and their associated probability. It’s difficult to interpret the lists of words and define associated topics. For instance:
u'0.055*app + 0.045*team + 0.043*contact + 0.043*idea + 0.029*quote + 0.022*free + 0.020*development + 0.019*looking + 0.017*startup + 0.017*build',
u'0.033*socialmedia + 0.022*python + 0.015*collaborative + 0.014*economy + 0.010*apple + 0.007*conda + 0.007*pydata + 0.007*talk + 0.007*check + 0.006*anaconda',
u'0.053*week + 0.041*followers + 0.033*community + 0.030*insight + 0.010*follow + 0.007*world + 0.007*stats + 0.007*sharing + 0.006*unfollowers + 0.006*blog',
u'0.014*thx + 0.010*event + 0.008*app + 0.007*travel + 0.006*social + 0.006*check + 0.006*marketing + 0.005*follow + 0.005*also + 0.005*time',
u'0.044*docker + 0.036*prodmgmt + 0.029*product + 0.018*productmanagement + 0.017*programming + 0.012*tipoftheday + 0.010*security + 0.009*javascript + 0.009*manager + 0.009*containers',
u'0.089*love + 0.035*john + 0.026*update + 0.022*heart + 0.015*peace + 0.014*beautiful + 0.012*beauty + 0.010*life + 0.010*shanti + 0.009*stories',
u'0.033*geek + 0.009*architecture + 0.007*code + 0.007*products + 0.007*parts + 0.007*charts + 0.007*software + 0.006*cryptrader + 0.006*moombo + 0.006*book',
u'0.049*stories + 0.046*network + 0.044*virginia + 0.044*entrepreneur + 0.039*etmchat + 0.025*etmooc + 0.021*etm + 0.015*join + 0.014*deis + 0.010*today',
u'0.056*slots + 0.053*bonus + 0.052*fsiug + 0.039*casino + 0.031*slot + 0.024*online + 0.014*free + 0.013*hootchat + 0.010*win + 0.009*bonuses',
u'0.056*video + 0.043*add + 0.042*message + 0.032*blog + 0.027*posts + 0.027*media + 0.025*training + 0.017*check + 0.013*gotta + 0.010*insider'
Fortunately, we can use LDAvis a fantastic library to explore and interpret LDA topic results. LDAvis maps topic similartiy by calculating a semantic distance between topics (via Jensen Shannon Divergence)
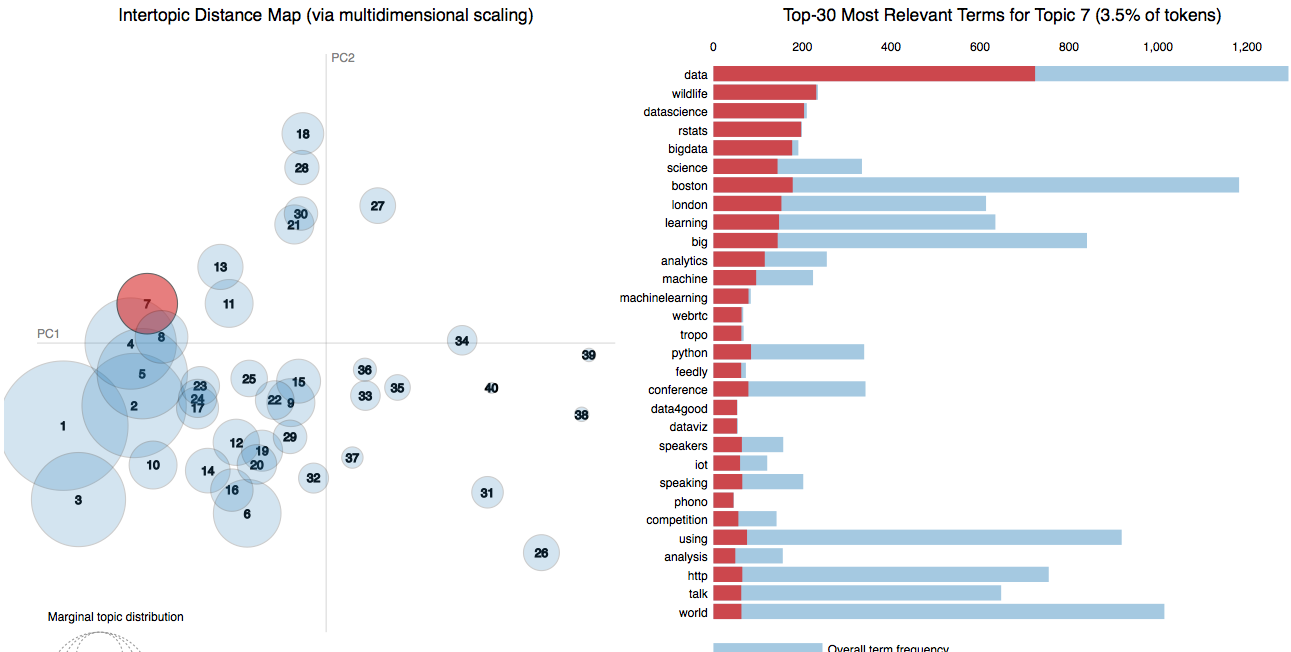
LDAvis is an extremely powerful tool to tune up your LDA model and visualize the cohesion of your topics.
The results of the topic modeling of my followers is available in this LDAvis notebook.
Too few topics (K=10) result in non cohesive topics all very similar to one another With 50 topics the topic spread is much better. But the best result was obtained with 40 topics, alpha = 0.001 and 100 passes. We also trained the model with 100 topics and 100 passes but did not notice any improvement in the coherence of the topics. All 3 models are presented in the LDAvis notebook
- 1 is about working life in general: work, love, well, time, people, email
- 2 is about the social tech world in Boston with discriminant words like: sdlc, edcampldr, … and the big social network company names
- 3 is more about brands and shopping: personal, things, brand, shop, love,
- 4 is about social media marketing: Marketing, hubspot, customers, … (and leakage from Project Management (pmp, exam))
- 5 is a mess and shows french words that leaked through our lang filtering
- 6 is about bitcoins
- 7 is about data science: rstats, bigdata, machinelearning, python, dataviz, …
- 8 is about rails and ruby and hosting. NewtonMa is also relevant as the ruby Boston meetup is in Newton MA.
- 9 is about casino and games
-
and 10 could be about learning analytics (less cohesive topic)
- 13 is about python, pydata, conda, …. (with a bit of angular mixed in)
Conclusion
LDA is not a magic wand! The model is difficult to train and the results need a solid dose of interpretation. This is especially true in the context of tweets that construct rather noisy documents. In an unsupervised context, estimating the performance of the model requires either manual assessment or some quality metric. Our manual assessment of the relevance of the topics found by the LDA model is not exhaustive. However it gives a strong indication that the method we followed is sound and does what it’s supposed to do.
Further ways to improve the LDA results would include
- Estimating the optimal number of Topics K in a more formal manner (likelihood measure, distance evaluation)
- Boosting hash tags in the model to reflect their importance (via the alpha parameter)
- Grid searching for the optimal set of LDA parameters
In the second part of this study, we carry out segmentation of the followers with Latent Semantic Analysis and K-Means and compare the results between LSA and LDA. Segmentation of Twitter Timelines via Topic Modeling
Resources and further readings
- See also this newest post on comparing and combining LSA and LDA
- The seminal paper on Latent Dirichlet Allocation (pdf) by Blei, Ng and Jordan
- Topic Modeling with gensim
- Introduction to Latent Dirichlet Allocation
- Finding structure in xkcd comics with Latent Dirichlet Allocation
- Using Latent Dirichlet Allocation to Categorize My Twitter Feed
- Topic Modeling for Fun and Profit a Notebook on Gensim by Radim Rehurek its creator
- Predicting what user reviews are about with LDA and gensim
Some videos / Notebooks on LDAvis
- Ben Maybe, SavvySharpa: Visualizing Topic Models
- LDAvis: A method for visualizing and interpreting topic models
- A pyLDAvis notebook
The code and notebook behind this post are:
- Extracting data from Twitter
- Preparing the documents for LDA
- Running LDA on previous corpus and dictionary
- LDAvis notebook of my followers timelines
Final Note: The first version of the python scripts were in 3.4. However after running into problems with LDAvis and the dictionary produced in 3.4 I reverted back to 2.7. I also found out that lda models saved in python 3 where not compatible with LDAvis for python 2. Switching back the whole stack to python 2.7 was the the path of least resistance.
Next: In the following article we compare LSA and LDA and show how these 2 methods can be combined for better results.